

Uji Halusinasi menggunakan Embedding-Based Assertion
Disclaimer : Kami belum tahu apakah pendekatan ini akan cukup applicable untuk diterapkan sebagai praktek pengujian sehari-hari. Namun kami rasa ilmunya sangat baik untuk dipelajari untuk mengerti bagaimana model bekerja dan mengulik cara mengujinya.
Kemarin kita sudah membahas menguji halusinasi menggunakan teknik blackbox dan heuristic. Jika dijabarkan lebih jauh sebenarnya masih banyak heuristic yang bisa dipakai. Yang menarik dengan mempelajari ini ternyata ada teknik non-heuristik dengan menggunakan statistik yang bisa dijadikan acuan untuk mengetahui level halusinasi dari output LLM. Secara statistik ditemukan perbedaan yang cukup signifikan antara respons yang berhalusinasi dan tidak sehingga bisa digunakan sebagai baseline.
Kali ini kita akan membahas teknik pengujian Halusinasi LLM dengan menggunakan teknik greybox menggunakan embedding-based assertion berdasarkan paper “Hallucination Detection: A Probabilistic Framework Using Embeddings Distance Analysis”.
Embedding Distance
Sebelumnya kita belajar dulu “Apaan tuh Embedding Distance?” ini pertanyaan pertama yang muncul ketika mempelajari paper tersebut.
Embedding adalah angka yang merepresentasikan suatu teks berdasarkan maknanya. Teks bisa berupa kata, kalimat, frase atau lebih panjang lagi seperti paragraf. Embedding distance adalah ukuran seberapa jauh perbedaan makna antara dua teks, bukan cuma kata melainkan seluruh konteks kalimat.
Pada paper ini, tim peneliti menggunakan Minkowski Distance untuk mengukur jarak antar semantik. Semakin jauh (angkanya semakin besar) maka semakin tidak relevan. Dari angka ini kita bisa menyimpulkan atau menetapkan threshold kapan model dianggap berhalusinasi.
Minkowski Distance
Sebelum membahas kode, kita perlu mengerti dulu berbagai macam distance metric yang dibahas pada paper tercantum Minkowski Distance : Manhattan, Euclidean dan Fractional.
Minkowski distance sendiri adalah formula umum untuk menghitung jarak antara dua titik. Dengan ini kita gunakan sebagai dasar bahwa semakin besar jaraknya begitu juga dengan makna semantiknya semakin bergeser. Lalu apa itu Manhattan, Euclidean dan Fractional?
Ilustrasi jarak Minkowski (p=1,p=2,p=0.5)

Apa perbedaan ketiga distance tersebut?

Dengan mengerti karakteristik tiap distance tersebut, kita jadi bisa memilih atau menetapkan threshold yang sesuai dengan kebutuhan aplikasi. Walaupun sebenernya bisa saja kita brute force tiap metrics dan thresholdnya untuk mencapai tujuan 😀
Cara Memanfaatkan Embedding-Based Assertion
Lalu bagaimana distance tersebut kita gunakan secara teknis untuk menguji. Langkah di bawah adalah cara versi sederhana untuk menerapkan embedding based assertion.
- Cari tools sentence embedding. Kami menggunakan SentenceTransformers
- Ubah model output menjadi embedding menggunakan tools seperti SentenceTransformes (yang akan kita coba saat ini)
- Siapkan reference embedding sebagai ground truth. Kita bisa analogikan sebagai expected output.
- Bandingkan hasil embedding output dengan embedding. Analoginya seperti membandingkan actual result dengan expected output.
- Gunakan metric jarak (seperti Manhattan, Euclidean, Fractional) yang sesuai dan kita bisa menilai apakah maknanya cukup mendekati dan sesuai
- Tetapkan threshold yang bisa memenuhi kriteria yang telah kita tetapkan
- Bandingkan tiap percobaan dan tentukan kombinasi metrics dan threshold yang sesuai dengan requirement.
Selanjutnya kita akan pelajari tools SentenceTransformers untuk melakukan embedding assertion.
SentenceTransformers
Tools yang akan kita gunakan adalah SentenceTransformers(ST) adalah tools untuk melakukan embedding dari model yang kita uji.
Kita akan melakukan asersi berdasarkan distancenya. Sehingga jika angkanya makin kecil maka semantik antar kalimat lebih mendekati yang bisa kita artikan minim halusinasi.
Contoh kode berdasarkan distance kami ambil dari websitenya seperti berikut
>>> model = SentenceTransformer("all-mpnet-base-v2")
>>> sentences = [
... "The weather is so nice!",
... "It's so sunny outside.",
... "He's driving to the movie theater.",
... "She's going to the cinema.",
... ]
>>> embeddings = model.encode(sentences, normalize_embeddings=True)
>>> model.similarity_fn_name = "euclidean"
>>> model.similarity(embeddings, embeddings)
tensor([[-0.0000, -0.7437, -1.3935, -1.3184],
[-0.7437, -0.0000, -1.3702, -1.3320],
[-1.3935, -1.3702, -0.0000, -0.9973],
[-1.3184, -1.3320, -0.9973, -0.0000]])
Algoritma kodenya adalah menggambarkan perbandingan menggunakan distance “euclidean”. Berikut kami jabarkan cara membaca hasilnya
- Pada cell (1,1) menunjukkan angka -0.0000 dimana kalimat pertama dibandingkan dengan dirinya sendiri, yang artinya sama persis.
- Kalimat 1 dibandingkan kalimat 2 jika menggunakan euclidean maka nilainya -0.7437 dibandingkan dengan kalimat 3(-1.3935) dan 4 (-1.3184) kalimat 1 dan 2 memiliki kedekatan makna dibanding dengan kalimat 3 dan 4
- Kalimat 3 dibandingkan kalimat 4 jika menggunakan distance euclidean maka nilainya -0.9973 lebih besar daripada -1.3935, -1.3702 Menggunakan nilai di atas bisa disimpulkan bahwa kalimat 1 dan 2 memiliki kedekatan makna semantik, dibandingkan kalimat 3 dan 4. Dan sebaliknya, kalimat 3 dan 4 lebih memiliki kedekatan semantik dibandingkan dengan kalimat 1 dan 2.
Perlu dicatat bahwa pada tools seperti SentenceTransformer, nilai Euclidean dan Manhattan ditampilkan dalam bentuk negatif agar perbandingannya konsisten dengan metric lain (seperti Cosine similarity) yaitu semakin besar nilainya, semakin mirip. Namun secara teori, nilai jarak tidak boleh negatif
Berikut adalah contoh snapshot kode yang kami gunakan untuk mempelajari teknik pengujian ini. Kode dibawah dibuatkan oleh tools Copilot menggunakan model GPT-4.1
Dan berikut adalah contoh hasil result

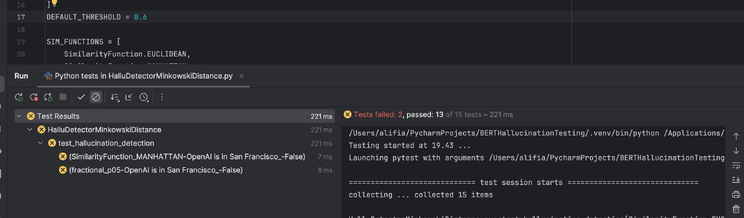
Dari contoh di atas kita bisa lihat threshold 0.6 akan menghasilkan pass rate lebih tinggi daripada threshold 0.7. Sehingga sebagai penguji kita bisa menyimpulkan bahwa threshold 0.6 akan lebih sesuai dengan requirement kita.
Caveat Embedding Based Assertion Testing
Untuk bisa memahami hasil pengujian dengan lebih baik, maka perlu diperhatikan beberapa poin berikut
- Tiap model memiliki vektor yang berbeda, sehingga memungkinkan ada diskrepansi pemetaan semantic sehingga hasilnya tidak selalu bisa sebanding.
- Lebih baik menggunakan real data ketika melakukan kalibrasi dalam menentukan threshold.
- Jika menggunakan lebih dari 1 macam distance, lebih baik threshold dibedakan. Contoh jika menggunakan kombinasi manhattan dan euclidean, coba kombinasikan thresholdnya misal 0.7 dan 0.8.
Potensi Peran Software Tester
Ini adalah potensi kegiatan yang bisa dilakukan oleh seorang software tester dalam menguji menggunakan embedding-based assertion
- Pemilihan embedding model yang sesuai
- Tidak ada satu metrics yang bisa mencakup seluruh requirement yang terdefinisi, untuk itu perlu mempelajari karakter tiap metric sehingga pemilihannya pun sesuai.
- Mengetahui requirement AI seperti apa yang diinginkan oleh stakeholder dan apa pengaruh threshold terhadap requirement yang diinginkan
- Menyiapkan ground truth dan test data yang baik dan sesuai dengan requirement.
- Bereksperimen dengan kombinasi parameter (threshold, tipe distance) yang menghasilkan pass rate paling baik.
Lesson learned : terpaksa belajar matematika lagi 😀
Tulisan ini dengan segala kekurangan adalah hasil ketikan sendiri bukan hasil generate dari AI. Namun tentu proses belajarnya kami sangat dibantu oleh AI. Jika ada ahli AI atau Data yang menemukan kesalahan atau kekurangan dari artikel ini, dengan sangat terbuka kami akan mengkoreksi.
Reference
- “Ricco, E., Cima, L., & Di Pietro, R. (2025). Hallucination Detection: A Probabilistic Framework Using Embeddings Distance Analysis. arXiv preprint arXiv:2502.08663. https://arxiv.org/abs/2502.08663
- https://huggingface.co/spaces/hesamation/primer-llm-embedding?section=what_are_embeddings?
- https://en.wikipedia.org/wiki/Minkowski_distance